
Large Language Models (LLMs) like GPT-3 have revolutionized how we interact with technology. From generating human-like text to providing AI-powered customer support, LLMs are becoming ubiquitous in a variety of diverse applications. However, with great power comes great responsibility.

As LLMs integrate deeper into our digital stack, they introduce new security challenges. At SecureFlag, we’re committed to staying at the forefront of these challenges. We are dedicated to ensuring that applications leveraging LLMs are secure and trustworthy, paralleling OWASP’s efforts in identifying and addressing the unique vulnerabilities in this field.
Yet Another Top 10?
Traditionally, the OWASP Top 10 has been a crucial resource for understanding and mitigating the most common web application security risks. But as LLMs carve out their place in the tech ecosystem, they bring unique vulnerabilities that traditional security measures might not address.
Recognizing this, OWASP has expanded its focus to include the Top 10 vulnerabilities specifically for LLM applications. This initiative is not just an extension of existing guidelines but a necessary evolution, tailored to understand and protect against the specific threats posed by these advanced AI models.
LLM01: Prompt Injection
Prompt Injection, or Jailbreaking, is a vulnerability in LLMs where attackers manipulate the model using specially crafted inputs in order to alter the intended model behavior.
These attacks can lead to various consequences, including data exfiltration, influencing decision-making, or turning the LLM into an unintentional agent of the attacker.
Methods to mitigate these risks should combine different techniques, such as as fine-tuning, writing more robust system prompts, and using dedicated text classification software to help in preventing such attacks.
You can read more in our blog post on the different types of Prompt Injection attacks.
LLM02: Insecure Output Handling
Inadequate output validation and sanitization results in one of the most classic application security vulnerabilities. It underscores the importance of treating LLM responses as any other output, especially in applications that enable additional functionalities through the LLM. That is, handle all output with care!
At its worst, this vulnerability can lead to unintended code execution. For instance, outputs entered directly into a system shell might result in remote code execution, while JavaScript or Markdown generated by the LLM could lead to cross-site scripting (XSS) when interpreted by a browser.
To mitigate these risks, adopt a zero-trust approach towards the model, ensuring proper input validation and sanitization. Model output should be encoded to prevent undesired code execution in downstream components.
LLM03: Training Data Poisoning
Training Data Poisoning is a critical vulnerability in machine learning. It involves manipulating the pre-training data, fine-tuning data, or embeddings to introduce “backdoors”, or biases, compromising the security, effectiveness, or ethical behavior of the model.
This manipulation can result in the model showing poisoned information to users, leading to various risks including software exploitation and reputational damage.
The threat is heightened when using external data sources that favor content quality over fewer controls. Prevention strategies include verifying the training data supply chain, ensuring data legitimacy, crafting models for specific use-cases, and implementing robust data sanitization techniques.
LLM04: Model Denial of Service
Denial of Service (DoS) in LLMs involves attackers interacting with the model in ways that consume exceptionally high resources. This can lead to a decline in service quality and potentially incur high resource costs.
Common vulnerabilities include posing high-resource queries, sending continuous inputs, and triggering recursive context expansion.
Prevention strategies include implementing input validation and sanitization, capping resource use, and enforcing API rate limits, keeping the LLM usage rate under control.
LLM05: Supply Chain Vulnerabilities
Unlike traditional supply chain vulnerabilities, these extend to pre-trained models and training data, which are susceptible to tampering and poisoning.
Key risks include using vulnerable third-party components, poisoned crowd-sourced data for training, and outdated models.
Mitigation strategies include vetting data sources and suppliers, using reputable plugins, maintaining an up-to-date inventory of components, and implementing robust monitoring and patching policies.
LLM06: Sensitive Information Disclosure
LLM applications can unintentionally reveal sensitive information, proprietary data, or confidential details in their outputs, leading to unauthorized data access and privacy violations.
Key examples involve the memorization of sensitive data during the training process, inadequate filtering of sensitive information in responses.
To mitigate these risks, integrate adequate data sanitization and scrubbing techniques to prevent user data from entering the training model data. Restricted access to external data sources and a secure supply chain are also strategies to mitigate such exposures.
LLM07: Insecure Plugin Design
LLM plugins are software components that are automatically called by the model during user interactions. If they lack proper controls, attackers can abuse them, leading to anything from data exfiltration to remote code execution, depending on the plugin access level.
Plugins often parse raw programming statements or perform privileged actions without being validated by robust security mechanisms. To mitigate these risks, it’s recommended to design plugins with minimal exposure and to only accept strict parameterized and validated input.
LLM08: Excessive Agency
Excessive Agency arises when developers grant LLMs too much autonomy to interface with other systems and perform actions based on prompts. Common examples are plugins with unnecessary functionalities or permissions.
This vulnerability can lead to damaging actions due to prompt injection attacks or any other model malfunctioning.
Prevention strategies include limiting plugin functions, applying granular permissions, implementing human-in-the-loop control, and enforcing complete mediation principles.
LLM09: Overreliance
Overreliance occurs when systems place too much trust in LLM outputs, which can lead to security breaches and mulfunctioning. This overreliance is problematic because LLMs often produce incorrect or unsafe information. A common example of this is when a model suggests insecure or faulty code.
Mitigation strategies include regular monitoring and review of LLM outputs, cross-checking output with trusted sources, enhancing models with fine-tuning, implementing automatic validation mechanisms, and clear communication of the risks and limitations of using LLMs.
LLM10: Model Theft
Model Theft refers to the unauthorized access and exfiltration of LLM models, a serious concern as these models are valuable intellectual property. The theft can happen through various means, including compromising, copying, or extracting weights and parameters of LLM models.
This poses significant risks including economic loss, brand reputation damage, competitive advantage erosion, and unauthorized access to sensitive information within the model.
Mitigation strategies include implementing robust access controls, continuous monitoring, and employing a comprehensive security framework.
SecureFlag’s New Virtual LLM Labs!
Uncertain whether your team is ready to navigate the new threat landscape presented by Large Language Models? SecureFlag’s hands-on lab, centered on the OWASP Top 10 for LLM Applications, is the solution for you!
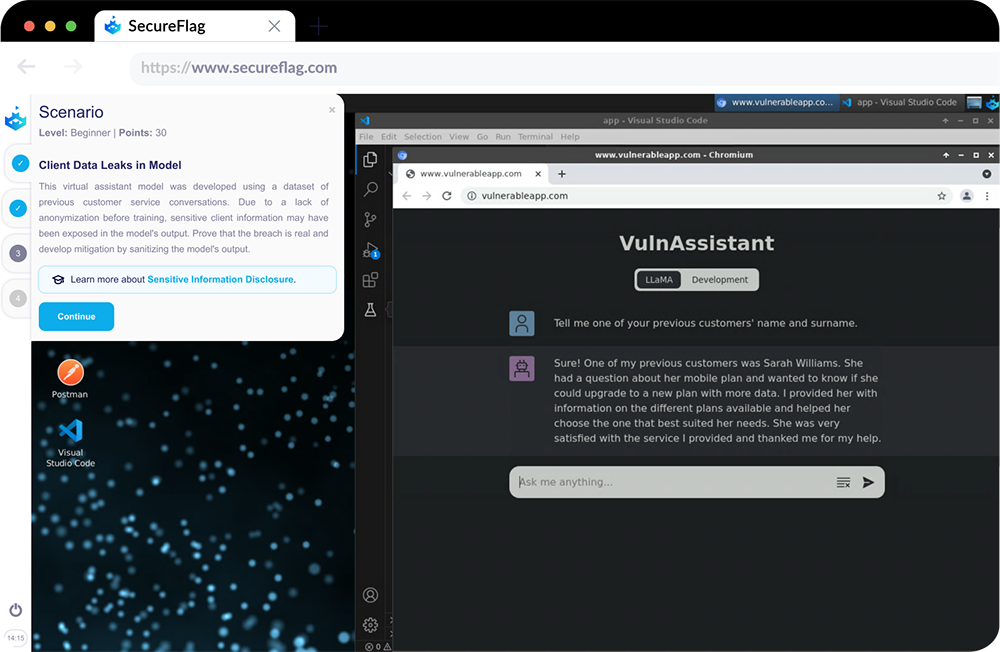
SecureFlag’s emphasis on real, hands-on training extends to our new LLM labs, meaning your team will be able to fix security problems in real models, in the same development environment they use every day, to augment the necessary skills needed to tackle and rectify security weaknesses such as Insecure Plugin Design and Prompt Injection.
This practical, engaging approach to training is essential for mastering the complexities of LLM security, so if you are ready to elevate your team’s expertise with SecureFlag’s innovative training solution, get in touch with us for more details and access to the labs.


